

Grafx-IT-Solutions
BIG DATA HADOOP
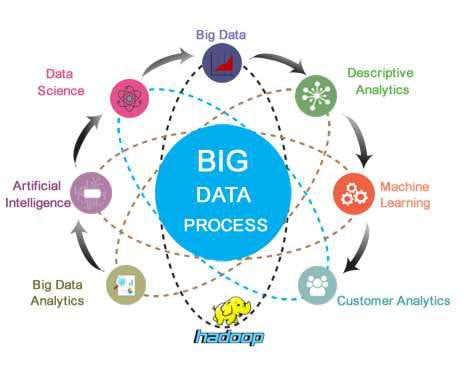
- About
- Duration
Apache Hadoop is an open-source framework for distributed storage and processing of large data sets across clusters of computers. It is a key technology in the field of big data, providing a scalable and cost-effective solution for handling massive amounts of diverse data. Hadoop's core components include the Hadoop Distributed File System (HDFS) for storage and the MapReduce programming model for parallel data processing. Hadoop enables organizations to analyze and derive insights from vast datasets, supporting businesses in making informed decisions. Its flexibility and ability to scale horizontally make it a foundational tool in the big data ecosystem.
Length :60 Hours
Course Content
- Introduction to HADOOP
- What is Big Data?
- What is Hadoop?
- Challenges With Big Data
- Comparison With Other Technologies
- Components of Hadoop Echo System
- HDFS
- Significance of HDFS in Hadoop
- Features of HDFS
- Storage aspects of HDFS
- HDFS Architecture
- Accessing HDFS
- MapReduce
- Why MapReduce is essential in Hadoop
- Processing Daemons of Hadoop
- Input Split
- Life Cycle
- Data Types
- Driver Code
- Natural Language Processing (NLP):
- Text processing and analysis.
Building NLP models for tasks like sentiment analysis and named entity recognition. - Reinforcement Learning:
- Basics of reinforcement learning.
Markov Decision Processes (MDPs), Q-learning, and policy gradient methods. - Model Deployment and Serving:
- Deploying machine learning models in real-world applications.
Integration with web services and APIs. - Ethical Considerations and Bias in Machine Learning:
- Understanding ethical implications of machine learning.
Addressing bias and fairness issues in model development. - Practical Projects:
- Hands-on projects to apply learned concepts.
Collaborative work on real-world datasets. - Case Studies and Industry Applications:
- Exploring real-world applications of machine learning in various industries.
Analyzing case studies to understand challenges and solutions.